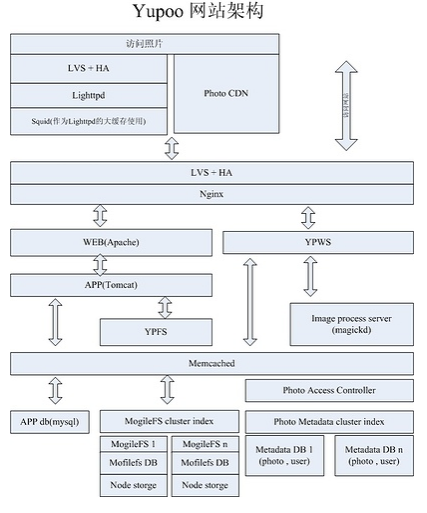
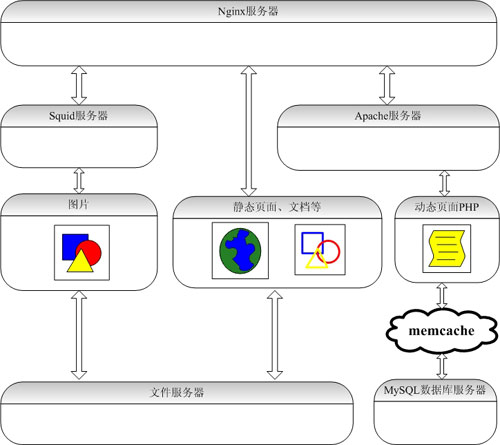
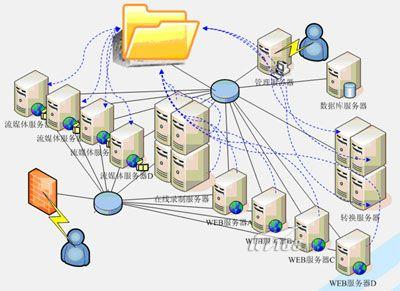
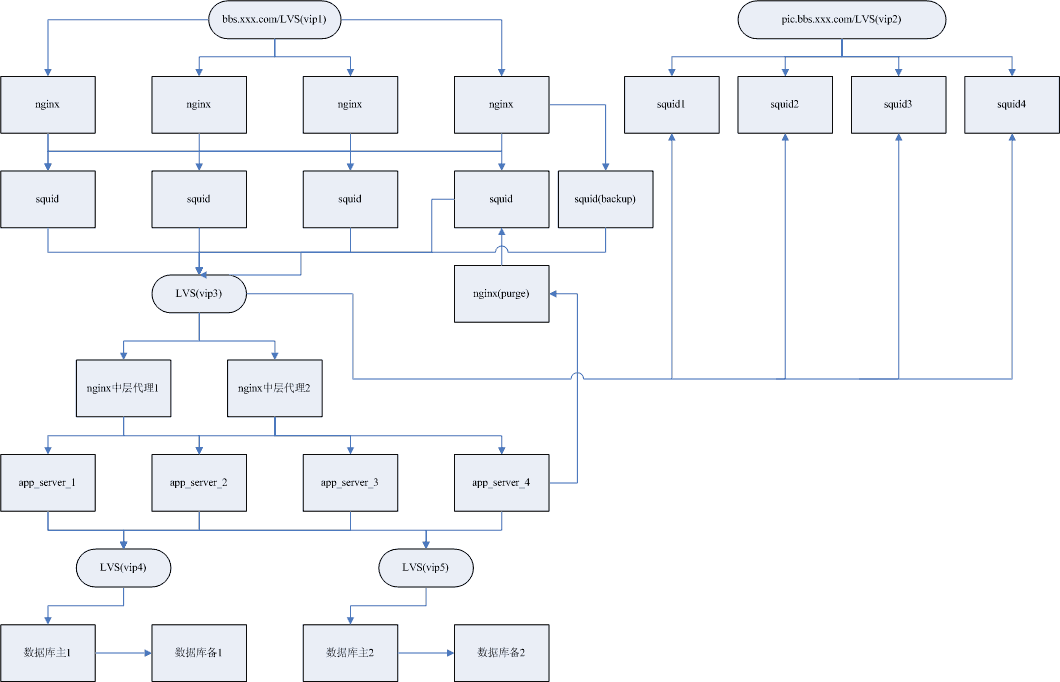
门户网站架构Nginx+Apache+MySQL+PHP+Memcached+Squid
服务器的大用户量的承载方案一、前言二、编译安装三、 安装MySQL、memcache四、 安装Apache、PHP、eAccelerator、php-memcache五、 安装Squid六、后记一、前言,准备工作当前,LAMP开发模式是WEB开发的首选,如何搭建一个高效、可靠、稳定的WEB服务器一直是个热门主题,本文就是这个主题的一次尝试。我们采用的架构图如下:引用——– ———- ————- ——— ————| 客户端 | ===> |负载均衡器| ===> |反向代理/缓存| ===> |WEB服务器| ===> |数据库服务器| ---->>阅读完整内容